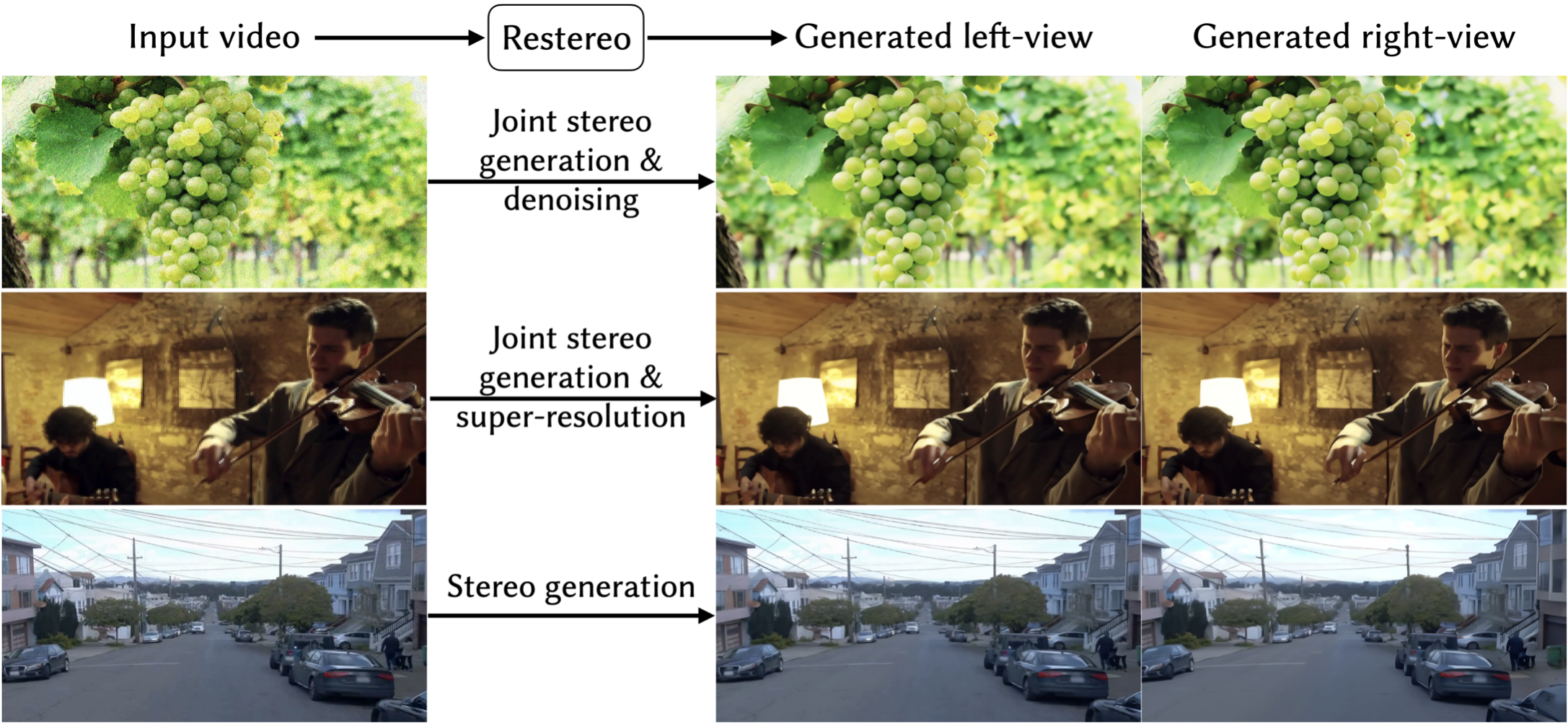
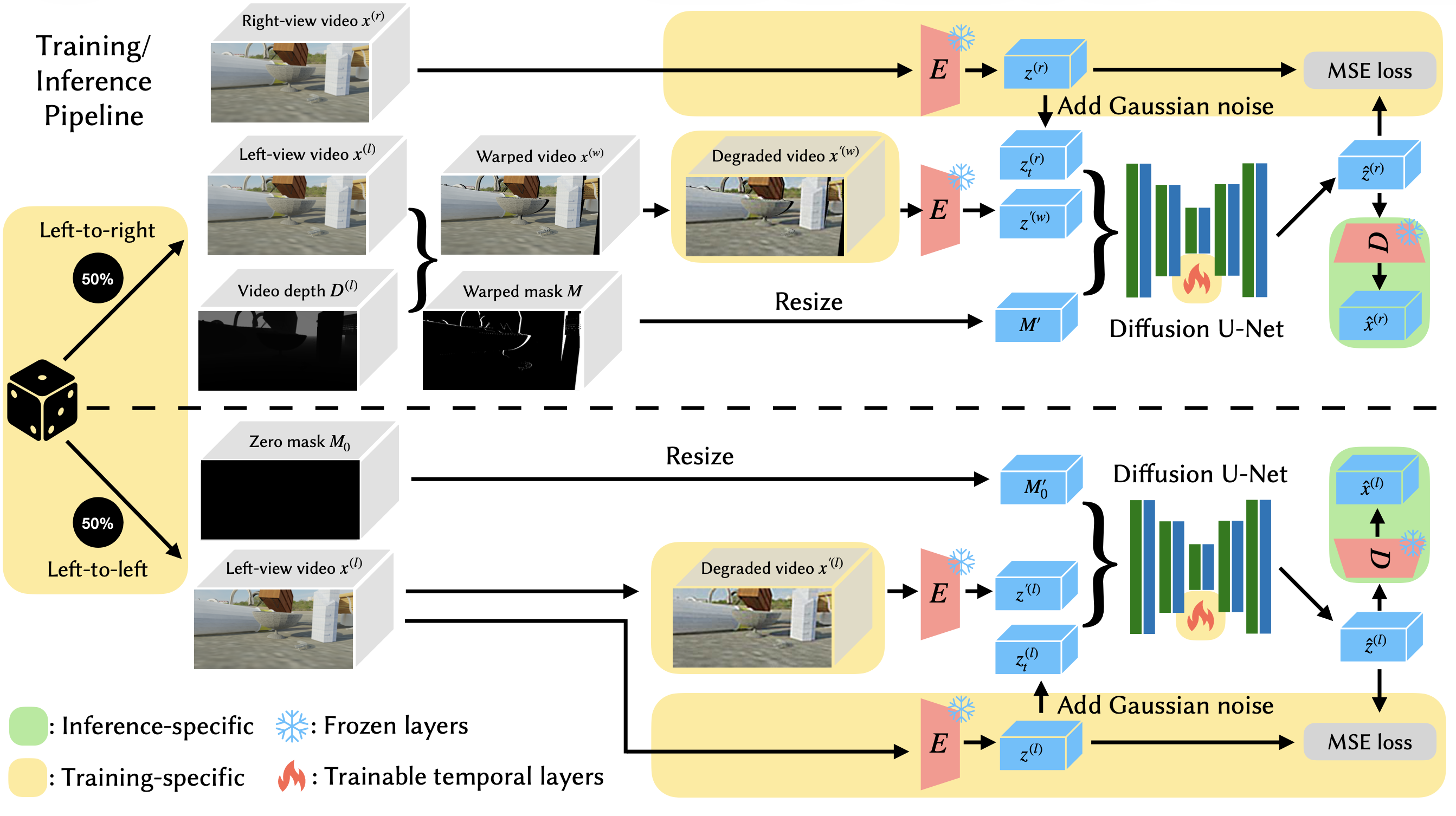
Stereo video generation has gained increasing interest, yet most recent video diffusion models remain limited to monocular outputs. Existing stereo approaches also struggle with degraded inputs and focus on stereo generation only. In this paper, we propose a unified diffusion framework that jointly performs stereo video generation and restoration from degraded video. The key idea is to inject video degradations during training and condition the model on warped masks, allowing it to learn robust two-view consistency directly from data, even though explicit view-consistency losses are not feasible in latent diffusion models. This design allows effective fine-tuning on small synthetic datasets and supports a single model that handles different degradation types, including downsampling and noise addition. Experiments show that our method outperforms existing baselines across varying levels of degradation, while matching their performance on non-degraded inputs and achieving a superior quality–time tradeoff.
Here we show the videos of all results presented in the main paper. Feel free to download the videos to check the quality via a VR headset, cross-eye view, or flipping the left-view and right-view to see the stereo effect.